

Contenido Duplicado en Webs
El contenido duplicado en Internet es un tema debatido con vehemencia cuando se trata de conocer cómo afecta a nuestro ranking en buscadores. Y se convierte en un asunto incluso más grave con el paso del tiempo cuando los remitentes de spam y otros usuarios malintencionados de Internet han llevado a la práctica el content scraping o robo del contenido de un sitio Web para utilizarlo ellos mismos con unos cuantos cambios de apariencia, y no del contenido. El robo de contenido se ha convertido en un problema tan grave que los buscadores ahora buscan texto duplicado, aun cuando está oculto detrás de un enlace como las Páginas similares que utiliza Google para el contenido relacionado (véase la figura 12.1). Si lo encuentran, nuestro sitio puede caer en los rankings o incluso ser eliminado de las listas completamente.
Google utiliza el enlace Páginas Similares para agrupar a los sitios Web con contenido relacionado.
No obstante, la cuestión del texto duplicado no es tan sencilla como pueda parecer. Algunas personas creen que hay demasiada preocupación sobre este tema, mientras que otros insisten en que el problema tiene que ser abordado. Y ambos tienen razón hasta cierto punto. Lo explicaremos a continuación.
En primer lugar, tenemos que comprender que no todo el contenido duplicado es de la misma clase. Debemos valorar algunas diferencias:
Reimpresiones: Es el contenido duplicado que se publica en varios sitios Web con la autorización del titular del copyright. Estos son los artículos que nosotros u otros crean y después distribuyen para crear enlaces «de retomo» a nuestro sitio Web o a sitios Web que sean relevantes para nuestro contenido. Las reimpresiones no son contenido duplicado perjudicial, aunque pueden hacer que nuestro sitio entre en el reino de las páginas similares, lo que implica que será enterrado detrás de otros resultados.
Creación de sitio Web espejo (site mirroring): Esta clase de duplicación puede provocar que uno o más de nuestros sitios sean eliminados de la lista de un buscador. Site mirroring significa literalmente mantener copias exactas de nuestro sitio Web en dos lugares diferentes en Internet. Los sitios Web suelen realizar esta práctica constantemente como una forma de evitar el tiempo de inactividad cuando un sitio Web cae. En la actualidad, las capacidades de los servidores son tan importantes que esta práctica ya no es tan necesaria, y los buscadores ahora ya «no incluyen» el contenido réplica debido a las implicaciones de envío de spam que pudiera tener. Se sabe que los remitentes de spam hacen réplicas de sitios para crear un
Internet falso» con el objetivo de robar nombres de usuario, contraseñas, números de cuenta, y otra información personal.
Robo de contenido (content scraping): Los ladrones de contenido extraen el contenido de un sitio Web y lo reutilizan en otro sitio Web haciendo únicamente cambios «estéticos». Esta es otra táctica utilizada por los remitentes de spam, y a menudo también es una fuente de incumplimientos de copyright.
Contenido duplicado en el mismo sitio Web: Si duplicáramos el contenido por todo nuestro propio sitio Web, también se nos podría penalizar por contenido duplicado. Esto se vuelve especialmente molesto con los blogs, porque a menudo hay todo un artículo completo del blog en la página principal y después un artículo archivado en otra página de nuestro sitio. Este tipo de duplicación se puede gestionar utilizando un post parcial, denominado snippet (fragmento), que vincula el artículo completo en un único lugar en nuestro sitio Web.
De estos tipos de contenido duplicado, dos son especialmente dañinos para nuestro sitio Web: la creación de un sitio Web espejo y el robo de contenido. Antes que utilizar site mirroring, deberíamos considerar otros métodos para crear una copia de nuestro sitio Web. Si utilizamos el robo de contenido podríamos enfrentamos a acciones legales por incumplimiento de copyright. El robo de contenido es una práctica que es mejor evitar completamente.
Aunque las reimpresiones y los duplicados del mismo sitio Web no son completamente perjudiciales, tampoco son útiles.
Y de hecho pueden ser perjudiciales si se manejan de forma incorrecta. No ganaremos puntos con un rastreador de buscadores si nuestro sitio está lleno de contenido que se está utilizando en cualquier otra parte en la Web. Las reimpresiones, especialmente aquellas que se repiten con frecuencia en la Web, harán que a la larga el rastreador empiece a darse cuenta de su presencia.
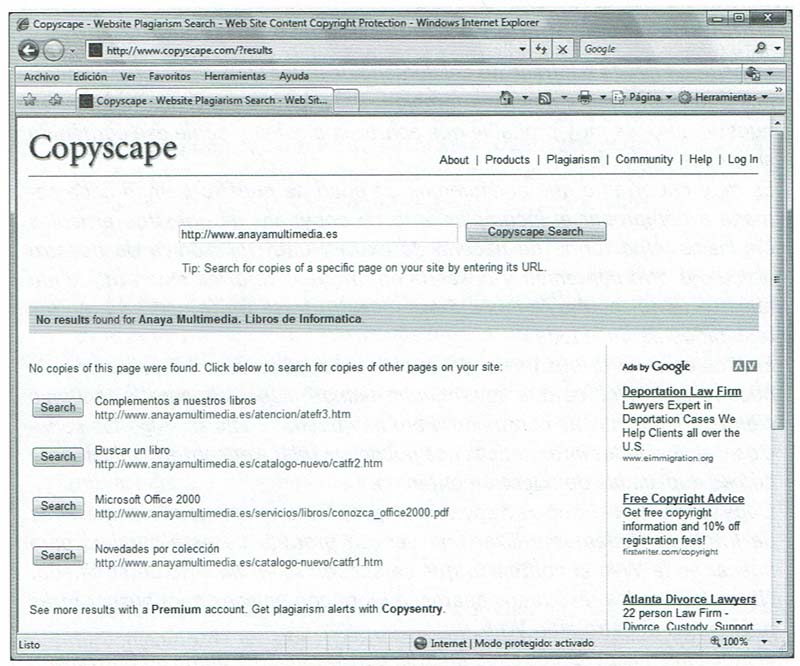
Copyscape comprueba Internet en busca de copias del contenido en nuestras páginas Web.
Una vez que se dé cuenta, el rastreador intentará encontrar la ubicación original de la reimpresión. Lo hará examinando el lugar en el que el contenido apareció por primera vez. También examinará a qué copia del texto apuntan la mayoría de los enlaces y qué versiones del artículo son el resultado del robo de contenido. Mediante un proceso de eliminación, el rastreador reducirá el campo hasta que se pueda tomar una determinación. Y si todavía es muy difícil decir dónde se originó el contenido, el rastreador escogerá de los dominios de confianza.
Una vez que el rastreador ha determinado qué contenido es el original, el resto de reimpresiones dejarán de utilizarse o serán eliminadas del indice.
Si tuviéramos que utilizar contenido que no es original, o si tuviéramos varias copias de contenido en nuestro sitio Web, hay una forma para evitar que esos duplicados afecten negativamente a nuestros ranking en buscadores. Utilizando las etiquetas <robots. txt> o <noindex>, podemos evitar que las páginas duplicadas sean indexadas por los buscadores.
La etiqueta <noindex> se debería situar en el encabezamiento header de la página que no queremos que sea indexada. También es una buena idea permitir al rastreador que encuentre la etiqueta para seguir enlaces que pudieran estar en la página. Para hacerlo, nuestro código (que es una metaetiqueta) debería parecerse a éste:
<meta name=robots» content=»noindex, follow’>
Esa pequeña etiqueta de código le dice al buscador que no indexe la página, pero que siga los enlaces en la página. Este pequeño trocito de código nos puede ayudar a solucionar el problema de que los buscadores lean nuestro contenido duplicado.
La etiqueta <robots . txt> se puede utilizar para conseguir un efecto similar, pero no lo trataremos en este post.Advertencia: No podemos cometer el error de utilizar la etiqueta como un método engañoso para ocultar el contenido duplicado que incluimos intencionadamente para aumentar nuestro ranking en buscadores. E/proceso con toda probabilidad tendrá consecuencias negativas. El rastreador a la larga se dará cuenta y descubriremos que nuestros ranking en buscadores comenzarán a caer.
Detener el incumplimiento del derecho de autor
El incumplimiento o infracción de/derecho de autor (copyright infringement) nos puede suceder a nosotros también. Si incluimos contenido original en nuestro sitio, es muy probable que aparezca alguien y copie ese contenido sin nuestro permiso.
Es muy importante que dediquemos un poco de nuestro tiempo cada semana a comprobar el incumplimiento de copyright de nuestros artículos originales. Una forma de hacerlo es extraer una frase única de nuestro artículo u otro contenido y buscarla en Internet. Si otros están utilizando nuestro texto, es muy probable que nuestra frase única aparezca en los resultados de búsqueda.
El problema de la búsqueda de copias no autorizadas del contenido de nuestro sitio Web es que lleva mucho tiempo, especialmente si tenemos cientos de páginas de contenido. Pero hay buenas noticias. Algunos servicios y aplicaciones informáticas nos pueden ayudar a encontrar rápidamente copias duplicadas de nuestro contenido.
Copyscape (www.copyscape.com) proporciona un servicio a través de Internet. Podemos utilizar una versión gratuita de este servicio para buscar en la Web el contenido que se encuentra en un URL determinado. Normalmente los resultados aparecen junto con enlaces para buscar otras páginas en nuestro sitio Web.
E/problema que podemos experimentar con la versión gratuita de Copyscape es que las páginas que devuelve en los resultados de búsqueda son páginas antiguas. Podría parecer que para obtener el mejor beneficio de Copyscape tuviéramos que pagar por la versión premium de la aplicación.
Copyscape no es caro. Copyscape Premium sólo cuesta 0,05 euros por búsqueda, y Copysentry, una aplicación que supervisa automáticamente la Web para buscar nuestro contenido, sólo cuesta 4,95 euros al mes.
Otro servicio que podemos utilizar para supervisar o buscar en la Web incumplimientos de derechos de autor es CyberAlert (www.cyberalert.com). Existen muchos otros servicios, que podríamos utilizar si fuera necesario.